Em um post anterior comecei uma série sobre Scala, focando em programadores Java. Porém notei que a curva de aprendizado de uma linguagem, principalmente em novo paradigma pode ser drástica demais. Portanto decidi focar mais no aprendizado do paradigma aproveitando o que puder do Java. Apesar de Java não ser funcional podemos aprender algumas técnicas interessantes e melhorar nossos projetos atuais.
Uma característica importante do paradigma funcional é o projeto dos tipos das linguagens. O uso de tipos como listas, mapas, árvores e conjuntos são enfatizados para a manipulação de dados. Nas linguagens mais puras os valores são imutáveis, logo as variáveis devem ser inicializadas com valores válidos. Note que isto é muito importante. Se precisamos inicializar nossas variáveis com valores válidos isso significa que nunca teremos variáveis nulas. O próprio inventor do conceito de nulo reconhece que isso é um erro.
Caso ainda esteja resistente a reconhecer este erro, lembre-se de quantas NullPointerException seu código de produção gerou, ou ao menos quanta complexidade foi adicionada ao código através de condicionais você teve de fazer verificando se algo é diferente de null.
Claro que podemos apelar para o Null Object Pattern, mas nem sempre é trivial e envolve muito trabalho em alguns casos.
O ideal seria o sistema de tipos da nossa linguagem nos ajudar com isso. Vamos ver um exemplo:
Option é uma classe abstrata que representa um tipo que pode ou não ter valor. Teremos mais duas subclasses, uma indicado a existência de valor e outro a ausência. O método hasValue() informará isso para nós através de sua implementação em cada subclasse. O método get() retornar o valor, caso este exista e por fim getOrElse(T alternative) retorna o valor da Option, caso este seja inexistente é retornada a alternativa passada como parâmetro. As coisas ficarão mais claras com a implementação das subclasses e uso.
Vamos ao subtipo que indica existência de valor:
Como Some representa a existencia de valor o método hasValue() sempre retorna true, o método get() o valor.
Agora o subtipo que representa ausência de valor:
Como None representa ausência de valor o método hasValue() sempre retornará falso, e lançaremos uma exceção caso seja tentado recuperar o valor que não existe. Já que None não possui valor, o método equals() sempre retorna true caso seja passada outra instância de None.
Agora vamos fazer uso do nosso novo sistema de tipos:
No código acima criamos 3 Options e iteramos sobre eles chamando o método getOrElse(T alternative), dessa forma, se existe um valor, o mesmo é retornado, caso contrário é retornado o valor alternativo.
Também podemos voltar á abordagem mais clássica, perguntando se existe valor no Option:
Chamamos o método hasValue para verificar se aquela Option possui um valor e então o usamos.
Por fim, vamos ver como fica o código dos nossos métodos que podem retornar um valor ou ausência de valor e seu uso:
Note que o grande ganho com essa abordagem é deixar explicito através de código que o valor que estamos usando é opcional, o retorno do método agora é um Option, bem mais legível e menos passível de erros, pois sendo um Option, devemos determinar se o Option é uma instância de Some antes de usar o valor.
Desenvolvendo nossas próprias classes para melhorar o sistema de tipos nesse caso, parece overhead, uma solução é o uso do Guava, uma lib que possui recursos interessantes que dão um "sabor"funcional para nossos projetos.
Aqui tem uma rápida introdução de como usar esses recursos com o Guava.
sexta-feira, 30 de agosto de 2013
segunda-feira, 12 de agosto de 2013
Por que preciso declarar como final variáveis passadas à classes anônimas (inner class)?
É muito comum quando estamos desenvolvendo interfaces gráficas seja em Swing ou Android o uso de classes anônimas, geralmente usamos classes anônimas como callbacks em listeners de eventos. Devido às características do Java, quando precisamos de um callback passamos uma instância de classe como parâmetro ao invés de simples funções como podemos fazer em Javascript por exemplo.
Repare que no código acima temos um erro, pois tentamos acessar a variável "content" dentro de uma inner class. Para resolver o problema é simples, basta declararmos "content" como final.
Para entender porque devemos declarar variáveis a serem acessadas em inner classes como final, devemos primeiro entender como inner classes são traduzidas em byte code.
Quando temos uma inner class ela não é gerada no mesmo arquivo de byte code da classe que a contém (outer class), são gerados dois arquivos, um com a outer class e outro com a inner class:
Classe1.class
Classe1$OnClickListener.class
Aqui surge um problema, nossa classe Classe1$OnClickListener.class precisa acessar a variável "content" declarada em Classe1.class. Para que isso seja possível o compilador cria em Classe1$OnClickListener.class um atributo que recebe uma cópia do valor da variável da outer class. Mas imagine que por algum motivo a variável em Classe1.class ou mesmo o atributo em Classe1$OnClickListener.class tenha seu valor alterado, teriamos um problema de sincronização de dados. Para evitar este problema somos obrigados a declararmos as variáveis que serão usadas em inner classes como final, assim os valores tanto nas outer classes e inner classes serão iguais.
Referências:
Repare que no código acima temos um erro, pois tentamos acessar a variável "content" dentro de uma inner class. Para resolver o problema é simples, basta declararmos "content" como final.
Para entender porque devemos declarar variáveis a serem acessadas em inner classes como final, devemos primeiro entender como inner classes são traduzidas em byte code.
Quando temos uma inner class ela não é gerada no mesmo arquivo de byte code da classe que a contém (outer class), são gerados dois arquivos, um com a outer class e outro com a inner class:
Classe1.class
Classe1$OnClickListener.class
Aqui surge um problema, nossa classe Classe1$OnClickListener.class precisa acessar a variável "content" declarada em Classe1.class. Para que isso seja possível o compilador cria em Classe1$OnClickListener.class um atributo que recebe uma cópia do valor da variável da outer class. Mas imagine que por algum motivo a variável em Classe1.class ou mesmo o atributo em Classe1$OnClickListener.class tenha seu valor alterado, teriamos um problema de sincronização de dados. Para evitar este problema somos obrigados a declararmos as variáveis que serão usadas em inner classes como final, assim os valores tanto nas outer classes e inner classes serão iguais.
Referências:
- http://stackoverflow.com/questions/7423028/java-local-variable-visibility-in-anonymous-inner-classes-why-is-final-keywo
- http://techtracer.com/2008/04/14/mystery-of-accessibility-in-local-inner-classes/
sexta-feira, 5 de abril de 2013
Scala para programadores Java
Você é um programador Java experiente, está sempre buscando conhecimento e novas formas de encontrar soluções. Uma forma de atingir este objetivo é aprender uma nova linguagem, preferencialmente com um paradigma diferente. Scala te chama atenção, por funcionar dentro da JVM, usar classes existentes do Java e por ser funcional, um paradigma que você ainda não conhece.
Então caro leitor temos muito em comum, na saga de estudar a linguagem e também o paradigma funcional, tive a oportunidade de receber a ajuda de umhacker amigo, @JonasAbreu. O coach do Jonas está sendo fundamental. Fui à minha primeira reunião dos ScalaDores, o grupo é bem avançado, portanto se você conhece bem Scala será um prato cheio, se está iniciando, também não tem problema, você acaba tendo um bom aproveitamento.
Uma grande questão é que você não gostaria de reaprender tudo que já sabe sobre programação, orientação a objetos e etc. Seria interessante se tivesse uma forma de aprender reaproveitando sua experiência, focando apenas nas novidades e de forma bem prática.
Pensando nisso, começo a partir deste post, fazer uma série para programadores Java interessados em aprender Scala. Abordarei tudo de forma muito prática e bem baseada em coisas que acho importante ou código que usei para alguma solução, MUITO DO CÓDIGO SERÁ AUTO EXPLICATIVO. Explicarei a teoria e detalhes quando o código não for tão obvio assim.
Para começar sugiro usar o interpretador de Scala no terminal. Instalar, iniciar o interpretador, tudo isso é bem fácil e já existe bons materiais, portanto não serão abordados aqui, ao menos nesse primeiro momento.
Vamos começar!
Então caro leitor temos muito em comum, na saga de estudar a linguagem e também o paradigma funcional, tive a oportunidade de receber a ajuda de um
Uma grande questão é que você não gostaria de reaprender tudo que já sabe sobre programação, orientação a objetos e etc. Seria interessante se tivesse uma forma de aprender reaproveitando sua experiência, focando apenas nas novidades e de forma bem prática.
Pensando nisso, começo a partir deste post, fazer uma série para programadores Java interessados em aprender Scala. Abordarei tudo de forma muito prática e bem baseada em coisas que acho importante ou código que usei para alguma solução, MUITO DO CÓDIGO SERÁ AUTO EXPLICATIVO. Explicarei a teoria e detalhes quando o código não for tão obvio assim.
Para começar sugiro usar o interpretador de Scala no terminal. Instalar, iniciar o interpretador, tudo isso é bem fácil e já existe bons materiais, portanto não serão abordados aqui, ao menos nesse primeiro momento.
Vamos começar!
Variáveis
Para declarar uma variável basta fazer:
var nomeDaVariavel = valor
Note que diferente do Java não precisamos declarar o tipo da variável, isso porquê Scala consegue, muitas vezes, inferir o tipo declarado. Mas caso quisermos declarar o tipo, por questões de legibilidade por exemplo, podemos fazer:
var nomeDaVariavel : TipoDaVariavel = valor
Também podemos criar uma variável "final" como em Java, para isso declaramos:
Assim se você tentar atribuir um novo valor à variável idadeFinal receberá um erro:
error: reassignment to val
A variável "nome" é do tipo String, Scala não tem uma classe String então ela usa classe java.lang.String do Java. Já "idade" é do tipo Int (scala.Int) que é correspondente ao tipo primitivo int, que temos no Java. Scala tem tipos correspondentes para os tipos primitivos do Java, por exemplo scala.Float para float, scala.Char para char. Quando seu código é compilado em bytecodes o compilador tenta usar os tipos primitivos do Java por questões de performance.
Funções
Funções requerem uma atenção especial, pois podemos encontrar a mesma função declarada de várias formas, o que pode assustar de início, mas depois que aprendemos fica bem fácil.
Para declarar uma função:
Temos sempre de declarar o tipo dos parâmetros, a função recebe dois parâmetros do tipo Int e retorna também um tipo Int. Note que após a declaração do tipo de retorno vem um sinal de igualdade "=" e então as chaves "{}" que é onde deve ficar o corpo do método.
Em alguns casos* Scala consegue inferir o tipo do retorno da função, como é o nosso caso. Então podemos declarar a mesma função omitindo o tipo de retorno:
Como nossa função possui apenas uma linha podemos também omitir as chaves:
* Se nossa função for recursiva temos de explicitar o tipo de retorno.
Podemos declarar funções sem retorno também:
Neste caso Unit é o equivalente ao void do Java. Você pode omitir o retorno neste caso também:
Um pouquinho de características funcionais
Uma das principais características de linguagens funcionais é poder passar funções como parâmetros. Vamos a um exemplo bem prático disso, vamos criar uma classe Array e forneceremos uma maneira de executar um "processamento" em cada elemento do array.
Para isso precisamos definir nossa interface Funcao<T> que possui o método executaEm:
Não se preocupe com relação ao código acima, voltaremos à essas características futuramente.
Funções
Funções requerem uma atenção especial, pois podemos encontrar a mesma função declarada de várias formas, o que pode assustar de início, mas depois que aprendemos fica bem fácil.
Para declarar uma função:
def funcao(param : TipoParam) : TipoRetorno = {
// corpo
}
Uma função que soma dois números:Temos sempre de declarar o tipo dos parâmetros, a função recebe dois parâmetros do tipo Int e retorna também um tipo Int. Note que após a declaração do tipo de retorno vem um sinal de igualdade "=" e então as chaves "{}" que é onde deve ficar o corpo do método.
Em alguns casos* Scala consegue inferir o tipo do retorno da função, como é o nosso caso. Então podemos declarar a mesma função omitindo o tipo de retorno:
Como nossa função possui apenas uma linha podemos também omitir as chaves:
* Se nossa função for recursiva temos de explicitar o tipo de retorno.
Podemos declarar funções sem retorno também:
Neste caso Unit é o equivalente ao void do Java. Você pode omitir o retorno neste caso também:
Um pouquinho de características funcionais
Uma das principais características de linguagens funcionais é poder passar funções como parâmetros. Vamos a um exemplo bem prático disso, vamos criar uma classe Array e forneceremos uma maneira de executar um "processamento" em cada elemento do array.
Para isso precisamos definir nossa interface Funcao<T> que possui o método executaEm:
Agora podemos usar nosso Array. Vamos supor que temos um Array de String, com nomes de pessoas e queremos apenas imprimir o nome das pessoas em maiúsculo.
Ficou bacana. Mas repare que precisamos de uma interface classe Funcao<T> que possui apenas um método. Depois precisamos de uma implementar essa interface (no nosso caso por uma classe anônima), tudo para executar o processamento do método, podemos resumir tudo isso. Em Scala temos o recurso de funções anônimas ou "function literal" que tornam as coisas bem interessantes, o mesmo código acima pode ser escrito como:
nomes.foreach(nome => println(nome)) // existem outras formas de escrever essa linha, abordaremos futuramente
Imagine quantas APIs poderiam se beneficiar dessa abordagem. Lembre-se da API do AWT/Swing. Era muito improdutivo desenvolver listeners para nossos elementos de tela (botões por exemplo). Ao invés de escrever uma classe anônima, implementar um método e etc, se reproduzirmos a API em uma linguagem funcional, podemos apenas passar uma função anônima como citado anteriormente.
Não se preocupe com relação ao código acima, voltaremos à essas características futuramente.
terça-feira, 18 de dezembro de 2012
Controle transacional: Spring + Vraptor
Controle de transação é sempre um ponto crítico em qualquer aplicação. Iniciar, tratar falhas e finalizar transações manualmente pode ser muito complicado, portanto muitas vezes usamos algum framework ou prática já consolidada para abordar o problema.
Você pode baixar esta classe na forma de plugin no Github de contribuições do Vraptor ou no meu particular.
Caso tenha alguma dúvida é só entrar em contato.
Em aplicações web uma abordagem muito utilizada é "uma transação por requisição", que consiste em abrir uma transação a cada requisição feita e no fim da lógica da requisição podemos efetuar o commit caso tudo tenha acontecido como esperado ou efetuar um rollback.
Note que você pode fazer isso em todos os seus servlets ou métodos dos controllers do seu framework mvc, mas dessa forma a tarefa será repetitiva e de difícil manutenção. Para melhorarmos o cenário, caso esteja trabalhando com uma aplicação usando uma api mais baixa como Servlets é possível usar um filter para implementar essa funcionalidade.
Note que você pode fazer isso em todos os seus servlets ou métodos dos controllers do seu framework mvc, mas dessa forma a tarefa será repetitiva e de difícil manutenção. Para melhorarmos o cenário, caso esteja trabalhando com uma aplicação usando uma api mais baixa como Servlets é possível usar um filter para implementar essa funcionalidade.
Com o Vraptor temos essa funcionalidade pronta, veja a documentação e o código. Se seguirmos a apostila oficial veremos que neste caso o Vraptor gerencia a SessionFactory, a Session e também nossos DAOs.
A motivação deste post foi um cenário encontrado em um projeto onde já possuíamos tudo gerenciado pelo Spring, inclusive transações e DAOs, não gostaríamos de refatorar tudo e ainda assim tirar proveito da abordagem de uma transação por requisição. Para quem quiser acompanhar como chegamos a solução segue o link do post no guj: http://www.guj.com.br/java/224207-vraptor3--hibernate--transactional-na-controller/4
Vamos ao código:
Criamos um DAO genérico:
E por fim o nosso interceptador de transações:
A motivação deste post foi um cenário encontrado em um projeto onde já possuíamos tudo gerenciado pelo Spring, inclusive transações e DAOs, não gostaríamos de refatorar tudo e ainda assim tirar proveito da abordagem de uma transação por requisição. Para quem quiser acompanhar como chegamos a solução segue o link do post no guj: http://www.guj.com.br/java/224207-vraptor3--hibernate--transactional-na-controller/4
Vamos ao código:
Este é o applicationContex.xml usado na aplicação, apenas declaramos o dataSource, nossa sessionFactory e também um transactionManager. Nada diferente de qualquer aplicação Spring normal.true true org.hibernate.dialect.MySQLDialect update true
Criamos um DAO genérico:
public abstract class GenericDAOHibernate<T> {
protected SessionFactory sessionFactory;
private final Class<T> persistentClass;
@Autowired
public GenericDAOHibernate(SessionFactory sessionFactory) {
this.persistentClass = (Class<T>) ((ParameterizedType) getClass().getGenericSuperclass())
.getActualTypeArguments()[0];
this.sessionFactory = sessionFactory;
}
public T load(Long id) {
return (T) this.getSession().get(this.persistentClass, id);
}
// outros métodos...
}
Uma implementação do nosso DAO
@Repository public class UserDAOHibernate extends GenericDAOHibernate{ @Autowired public UserDAOHibernate(SessionFactory sessionFactory) { super(sessionFactory); } @Override public User getUserByLogin(String login) { //... } // outros métodos... }
E por fim o nosso interceptador de transações:
@Intercepts
public class SpringTransactionInterceptor implements Interceptor {
private PlatformTransactionManager transactionManager;
private final Validator validator;
public TransactionInterceptor(PlatformTransactionManager transactionManager, Validator validator) {
this.transactionManager = transactionManager;
this.validator = validator;
}
@Override
public void intercept(InterceptorStack stack, ResourceMethod method, Object resourceInstance)
throws InterceptionException {
TransactionDefinition def = new DefaultTransactionDefinition();
TransactionStatus status = transactionManager.getTransaction(def);
try {
stack.next(method, resourceInstance);
if (!validator.hasErrors()) {
transactionManager.commit(status);
}
} finally {
if (!status.isCompleted()) {
transactionManager.rollback(status);
}
}
}
@Override
public boolean accepts(ResourceMethod method) {
return true;
}
}
Note que você pode tanto neste interceptor, quanto no padrão do Vraptor, sobreescrever os comportamentos. Um exemplo seria interceptar apenas métodos anotados com uma anotação própria.Você pode baixar esta classe na forma de plugin no Github de contribuições do Vraptor ou no meu particular.
Caso tenha alguma dúvida é só entrar em contato.
segunda-feira, 15 de outubro de 2012
Melhorando o cenário de testes com padrões de projeto Builder e Fluent Interface
Como sabemos, testar garante que nosso código tenha mais qualidade, seja mais conciso e elegante e também conhecemos a importância de testar nossas aplicações. Porém testar gera mais código e devemos dar ao código de teste a mesma atenção que damos ao código de produção, para que os testes sejam fáceis de entender e não se tornem difíceis de serem mantidos. Pois caso isso aconteça a equipe pode ficar desmotivada para realizar os testes.
Imagine que estamos desenvolvendo um sistema para uma loja de venda de computadores. Este sistema deve sugerir computadores que possam agradar determinado cliente.
Um possível modelo para este domínio pode ser visto no diagrama (diagrama informal, ok?!) abaixo:
Um possível modelo para este domínio pode ser visto no diagrama (diagrama informal, ok?!) abaixo:

Cada componente possui nome, descrição e cor.
Cor por sua vez possuí um nome e valores correspondente a tabela de cores RGB (red, green, blue).
Vamos ao código do domínio:
public class Computador {
private USB usbDianteira;
private USB usbTraseira;
private Collection< Componente > componentes;
private boolean marcaFamosa;
public Computador(USB usbDianteira, USB usbTraseira, Collection< Componente > componentes, boolean marcaFamosa) {
this.usbDianteira = usbDianteira;
this.usbTraseira = usbTraseira;
this.componentes = componentes;
this.marcaFamosa = marcaFamosa;
}
// getters e setters necessários
}
public class USB {
private String versao;
public USB(String versao) {
this.versao = versao;
}
// getters e setters necessários
}
public class Componente {
private String nome;
private String descricao;
private Cor cor;
public USB(String nome, String descricao, Cor cor) {
this.nome = nome;
this.descricao = descricao;
this.cor = cor;
}
// getters e setters necessários
}
public class Cor {
private String nome;
private int r;
private int g;
private int b;
public USB(String nome, int r, int g, int b) {
this.nome = nome;
this.r = r;
this.g = g;
this.b = b;
}
// getters e setters necessários
}
Agora que temos nosso modelo pronto, iremos testar a classe que verifica se devemos sugerir determinado computador ao cliente ou não. Esta classe recebe o Cliente no construtor e podemos chamar o método deveSugerir, que recebe um computador e retorna um boolean.
public class Aconselhador {
private Cliente client;
public Aconselhador(Cliente cliente) {
this.cliente = cliente;
}
public boolean deveReceberComoSugestao(Computador computador) {
// faz uma lógica baseada no cliente no computador a ser sugerido
}
}
Vamos testar nossa classe, para fins didáticos vamos testar apenas um caso da classe, porém em seu código, você deve testar TODAS as possibilidades. (Veja o post anterior para aprender como visualizar a cobertura de testes em seu código).@Test
public void deveSugrirComputadorDeMarcaEComMuitosComponentesParaClienteExigente() {
Cliente cliente = new Cliente("Renan");
USB usbDianteira = new USB("2.0");
USB usbTraseira = new USB("1.0");
Cor corDoMonitor = new Cor("preto", 0, 0, 0);
Componente monitor = new Componente("nome do monitor", "descricao monitor", corDoMonitor);
Cor corDoMouse = new Cor("preto", 0, 0, 0);
Componente mouse = new Componente("descricao do mouse", "nome mouse", corDoMouse);
Cor corDoTeclado = new Cor("branco", 100, 100, 100);
Componente teclado = new Componente("nome do teclado", "descricao teclado", corDoMonitor);
Cor corDaWebCam = new Cor("cinza", 140, 120, 110);
Componente webCam = new Componente("nome da webcam", "descricao webcam", corDaWebCam);
List< Componente > componentes = new ArrayList<>();
componentes.add(monitor);
componentes.add(teclado);
componentes.add(webCam);
Computador computador = new Computador(usbTraseira, usbDianteira, componentes, true);
assertTrue(new Aconselhador(cliente).deveReceberComoSugestao(computador));
}
Vamos analisar o código e fazer algumas considerações. A primeira coisa a notar é que quanto mais Componentes nosso Computador possuir, mais poluído fica nosso código. Também sem uma explicação prévia, fica difícil saber oque é o cada argumento inteiro passado para o construtor da classe Cor, o mesmo acontece para o argumento boolean passado para o construtor de Computador. Note que apenas lendo o código de teste não temos a mínima ideia do que significa cada um desses argumentos.
Note que instanciar tantos objetos, com tantas relações se torna propenso a erros.
Nosso Computador recebe uma Collection de Componentes, logo podemos declarar um Componente porém podemos esquecer de passá-lo para a lista de Componentes passada ao Computador. Como aconteceu com o componente "mouse", outro erro é que o objeto corDoMonitor foi passado como parâmetro para o construtor do teclado, repare o código.
Por fim, nosso Computador recebe dois argumentos do tipo USB, porém oque significa o primeiro? E o segundo? Qual deles representa a USB dianteira, e qual da USB traseira? No código acima, invertemos a ordem das USB.
Veja que este é um ponto bem propício a erros: é difícil saber a ordem quando temos dois ou mais argumentos do mesmo tipo sendo recebidos. O mesmo acontece com a classe cor, qual a ordem de tons ela recebe? Vermelho, verde, azul? Apesar de fugir da convenção nada impediria ser Verde, vermelho, azul, por exemplo. E também nos atributos String recebidos pela classe Componente.
Veja que este é um ponto bem propício a erros: é difícil saber a ordem quando temos dois ou mais argumentos do mesmo tipo sendo recebidos. O mesmo acontece com a classe cor, qual a ordem de tons ela recebe? Vermelho, verde, azul? Apesar de fugir da convenção nada impediria ser Verde, vermelho, azul, por exemplo. E também nos atributos String recebidos pela classe Componente.
É impossível apenas ler o código que cria o cenário de teste e entender todas as informações.
Porém podemos reverter essa situação com a aplicação dos padrões de projeto Builder e Fluent Interface.
O Builder torna a criação dos objetos mais fácil. Nos ajuda através de métodos com nomes significativos a entender oque estamos declarando e elimina as ambiguidades que podem ocorrer na passagem de parâmetros com o mesmo tipo, como no caso dos parâmetros USB na classe Computador e int na classe Cor.
Com Fluent Interface é possível dar mais fluidez à sintaxe e em alguns casos economizar boas linhas de código.
Vamos aos exemplos práticos. Começamos criando a classe ComputadorBuilder:
public class ComputadorBuilder {
private USB usbDianteira;
private USB usbTraseira;
private List< Componente > componentes = new ArrayList<>();
private boolean possuiMarcaFamosa;
public ComputadorBuilder comUSBDianteira(USB usbDianteira) {
this.usbDianteira = usbDianteira;
return this;
}
public ComputadorBuilder comUSBTraseira(USB usbTraseira) {
this.usbTraseira = usbTraseira;
return this;
}
public ComputadorBuilder comMarcaFamosa() {
this.possuiMarcaFamosa = false;
return this;
}
public ComputadorBuilder comComponente(Componente componente) {
this.componentes.add(componente)
return this;
}
public Computador build() {
return new Computador(this.usbDianteira, this.usbTraseira, this.componentes, possuiMarcaFamosa);
}
}
Veja que todos os métodos começam com a palavra "com", convencionamos assim, para que fique mais fácil autocompletar o nome dos métodos através da ide.
Vamos ao builder da classe Componente:
public class ComponenteBuilder {
private String nome;
private String descricao;
private Cor cor;
public ComponenteBuilder comNome(String nome) {
this.nome = nome;
return this;
}
public ComponenteBuilder comNome(String descricao) {
this.descricao = descricao;
return this;
}
public ComponenteBuilder comCor(Cor cor) {
this.cor = cor;
return this;
}
public Componente build() {
return new Componente(this.nome, this.descricao, this.cor);
}
}
E por fim o builder da classe Cor:
public class CorBuilder {
private String nome;
private int r;
private int g;
private int b;
public CorBuilder comNome(String nome) {
this.nome = nome;
return this;
}
public CorBuilder comR(int r) {
this.r = r;
return this;
}
public CorBuilder comR(int g) {
this.g = g;
return this;
}
public CorBuilder comB(int b) {
this.b = b;
return this;
}
public Cor build() {
return new Cor(nome, r, g, b);
}
}
Agora vamos refatorar nosso teste, note que podemos encadear a chamada de nossos builders, criando assim uma fluidez ainda maior.
@Test
public void deveSugrirComputadorDeMarcaEComMuitosComponentesParaClienteExigente() {
Computador computador = new ComputadorBuilder()
.comUSBDianteira(new USB("2.0"))
.comUSBTraseira(new USB("1.0"))
.comComponente(new ComponenteBuilder()
.comNome("nome do monitor")
.comDescricao("descricao monitor")
.comCor(new CorBuilder()
.comNome("preto")
.comR(0)
.comG(0)
.comB(0)
.build()
)
.build()
)
.comComponente(new ComponenteBuilder()
.comNome("nome do mouse")
.comDescricao("descricao mouse")
.comCor(new CorBuilder()
.comR(0)
.comG(0)
.comB(0)
.build()
)
.build()
)
.comComponente(new ComponenteBuilder()
.comNome("nome do teclado")
.comDescricao("descricao teclado")
.comCor(new CorBuilder()
.comR(100)
.comG(100)
.comB(100)
.build()
)
.build()
)
.comComponente(new ComponenteBuilder()
.comNome("nome webcam")
.comDescricao("descricao webcam")
.comCor(new CorBuilder()
.comR(140)
.comG(120)
.comB(110)
.build()
)
.build()
)
.build();
Cliente cliente = new Cliente("renan");
assertTrue(new Aconselhador(cliente).deveReceberComoSugestao(computador));
}
Apesar de nosso teste ter ficado com um número de linhas bem maior depois de refatorado, ganhamos muita expressividade, qualquer pessoa que ler o código entenderá o significado de cada argumento passado. E também ganhamos mais velocidade na hora de criar os objetos, decorrente da expressividade.
Bônus:
Padrões de projeto são como receitas, podemos segui-los, porém podemos adicionar nossos ingredientes a gosto, ou seja, não existe uma única forma de implementar um padrão. Note que usamos duas instâncias da classe Cor idênticas. Apesar de não estar descrito na do padrão builder, podemos criar um método estático para retornar um objeto com características fixas que usamos com frequência.
Algo como:
public static Cor corPreta() {
return new Cor("preto", 0, 0, 0);
}
domingo, 12 de agosto de 2012
Colorindo seu código para garantir qualidade instantânea com EclEmma
O TDD nos ajuda a desenvolver código coeso e influencia no design do nosso código, o tornando melhor, além de obviamente garantir testes de nossas funcionalidades.


Podemos também utilizar ferramentas de métricas e cobertura de código para garantir a qualidade de nosso projeto. Como por exemplo o Cobertura, uma ferramenta que mede o percentual de linhas cobertas por testes em nosso código.
Durante a fase de testes e desenvolvimento podemos querer saber de forma prática oque nossos testes estão cobrindo e onde esquecemos de testar, especialmente quando estamos trabalhando com código legado. Seria excelente se ao rodarmos um teste, a IDE já nos fornecesse essa informação.
Felizmente existem plugins que conseguem fazer este trabalho. Dentre eles o eCobertura e o EclEmma.
Vou demonstrar o uso do EclEmma através de um exemplo trivial.
O primeiro passo é instalar o plugin no Eclipse, para isso vá ao Marketplace do Eclipse (Help > Marketplace...), busque por eclemma e clique em install. A partir daí é só realizar os passos de uma instalação de plugin normalmente.
Agora vamos escrever um simples código para entender o funcionamento.
Vamos escrever testes para a classe legada Calculadora, esta possui um método chamado calcula, que dado um valor e um boolean decide se soma mais 10 ao valor.
Se o valor for maior que 100 ou o boolean passado seja true, então soma-se 10 ao valor, caso contrário não faz nada.
public class Calculadora {
public double calcula(double valor, boolean aplicaTaxas) {
double valorCalculado = valor;
if(valor > 100 || aplicaTaxas) {
valorCalculado += 10;
}
return valorCalculado;
}
}
Vamos escrever nosso primeiro teste:
@Test
public void naoDeveCalcularPoisValorEMenorQue100ENaoAplicaTaxas() {
Calculadora calc = new Calculadora();
double valorCalculado = calc.calcula(80, false);
assertTrue(valorCalculado == 80);
}
Para rodar o teste com o plugin clique com o direito sobre o arquivo de testes ou em seu código e vá a opção Coverage as... JUnit Test, pelo atalho Alt + Shift + E e T.
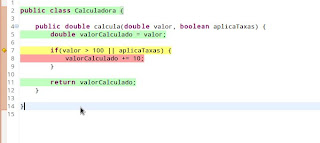
Navegue até a classe calculadora e veja como nosso código ficou colorido:

Repare que as linhas cobertas pelo teste ficaram verdes, com exceção da linha 7, que está amarela e da linha 8, que está vermelha.
Isso significa que a linha 7 não foi totalmente testada, ou seja, depois de rodar o teste, todas suas condições não foram realizadas (passe o mouse sobre o losango para ver a dica).
Vamos criar mais um teste para entrarmos na condicional. Agora passando o valor como 110 e aplicaTaxas como false:
@Test
public void deveCalcularPoisValorEMaiorQue100() {
Calculadora calc = new Calculadora();
double valorCalculado = calc.calcula(110, false);
assertTrue(valorCalculado == 120);
}
Vamos ao resultado:

Note que a linha 8, que antes era vermelha, agora está verde, conseguimos criar um teste que cobre este caso. Porém a linha 7 ainda está amarela (passando o mouse sobre o losango vemos que falta apenas uma condicional não coberta).
Vamos à um ultimo teste que simula o cenário ainda não coberto: Passar o parâmetro aplicaTaxas como true.
@Test
public void deveCalcularPoisAplicaTaxas() {
Calculadora calc = new Calculadora();
double valorCalculado = calc.calcula(20, true);
assertTrue(valorCalculado == 30);
}
Pronto, nossa lógica foi completamente testada.

Um excelente exercício que fiz foi desenvolver essa mesma classe usando TDD. Conforme você desenvolve o teste e codifica a implementação, já tem automaticamente 100% de cobertura. Porém se tivesse tomado essa abordagem não conseguiria mostrar como a ferramenta ajuda colorindo as linhas não testadas.
segunda-feira, 27 de fevereiro de 2012
Como configurar um projeto web com Maven + Eclipse
Algum tempo atrás estava procurando como configurar a dupla Eclipse + Maven para um projeto web e não consegui encontrar em um único site as instruções para realizar a tarefa, então estou escrevendo este guia para auxiliar os desenvolvedores com a mesma dificuldade.
Uso o Maven apenas para gerenciar as dependências, portanto a configuração realizada foi a mais simples possível para rodar o projeto.
O primeiro passo é instalar o m2e. Caso esteja usando o Eclipse Indigo basta ir no menu Help, depois Eclipse Market Place. Digite na caixa de busca m2e e instale o plugin.
O próximo passo é criar um Maven Project. Vá em File, New, Other e então procure por Maven Project.
Selecione a opção Create a simple project. Preencha o Group Id e Artifact Id do projeto, em Packing escolha a opção war, por se tratar de um projeto web.

Com o projeto criado, clique com o direito no projeto e escolha Properties >> Project Facets >> Convert to faceted from...
Marque a opção Dynamic Web Module.
Clique em Further Configuration avaliable e altere o Content Directory para: /src/main/webapp. Pressione OK.

Agora faremos com que as libs gerênciadas pelo maven sejam incluidas no deploy. Vá novamente nas propriedades selecione Deployment Assembly >> Add >> Java Build Path Entries >> Maven Dependencies.

Pronto! Agora é só adicionar suas dependências no pom.xml.
Abraços
Assinar:
Comentários (Atom)